Abstract
Demo
This is a data demo in our SVBench. The video is playing at 2x speed.
Overview
A temporal dialogue path represents a conversation within a video progressing over time. Our SVBench evaluates the capabilities of LVLMs in long-context streaming video understanding by constructing temporal dialogue paths to assess 9 critical skills.
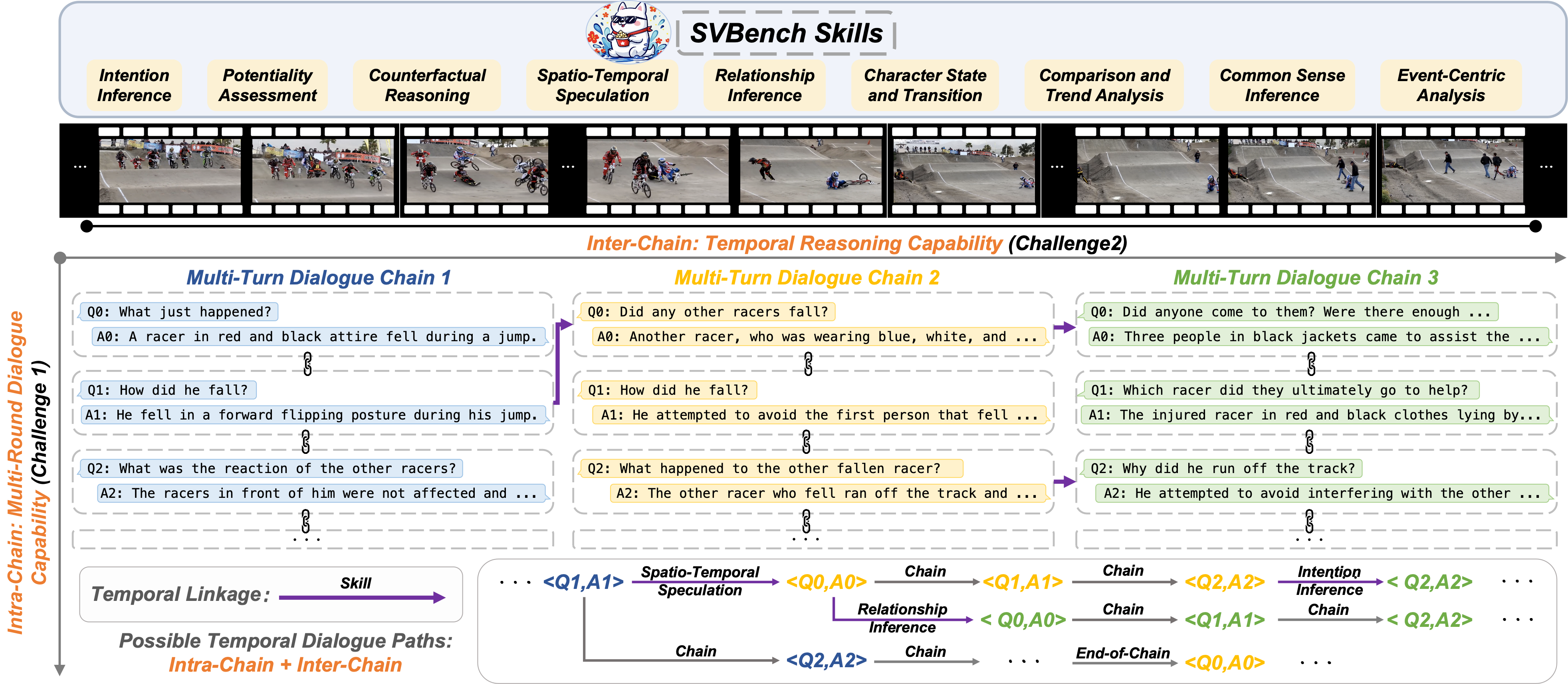
Figure 1: Illustration of temporal multi-turn dialogues.
Annotation Pipeline
Overview of the proposed SVBench framework:
(1) Filtering raw videos from diverse streaming sources; (2) Detecting scenes and splitting videos accordingly; (3) Constructing QA chains for dialogues within videos; (4) Performing manual annotation and quality assessment; (5) Identifying temporal linkages between QA chains; (6) Connecting QA chains to facilitate temporal reasoning; (7) Building temporal dialogue paths for evaluating LVLMs.
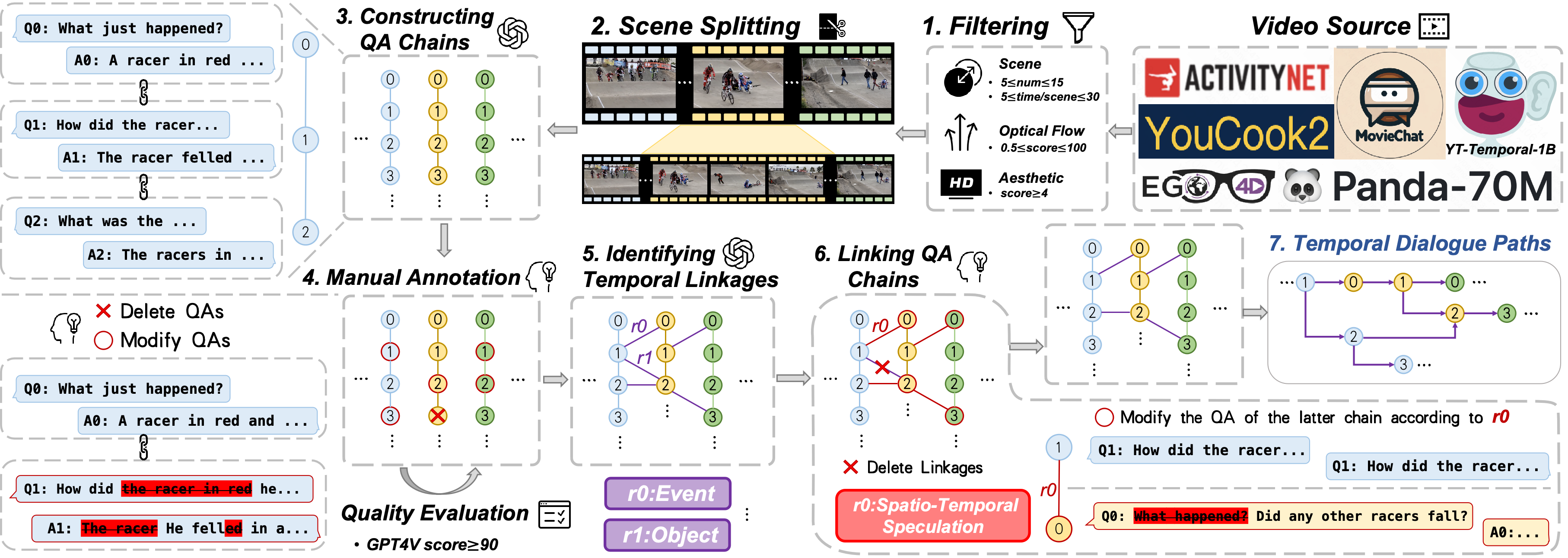
Figure 2: Overview of the proposed SVBench framework.
Statistical Analysis
Our dataset contains videos organized into 12 primary categories and 36 subcategories. To facilitate a more comprehensive evaluation of the capabilities of LVLMs, we classify the questions into 9 distinct categories.
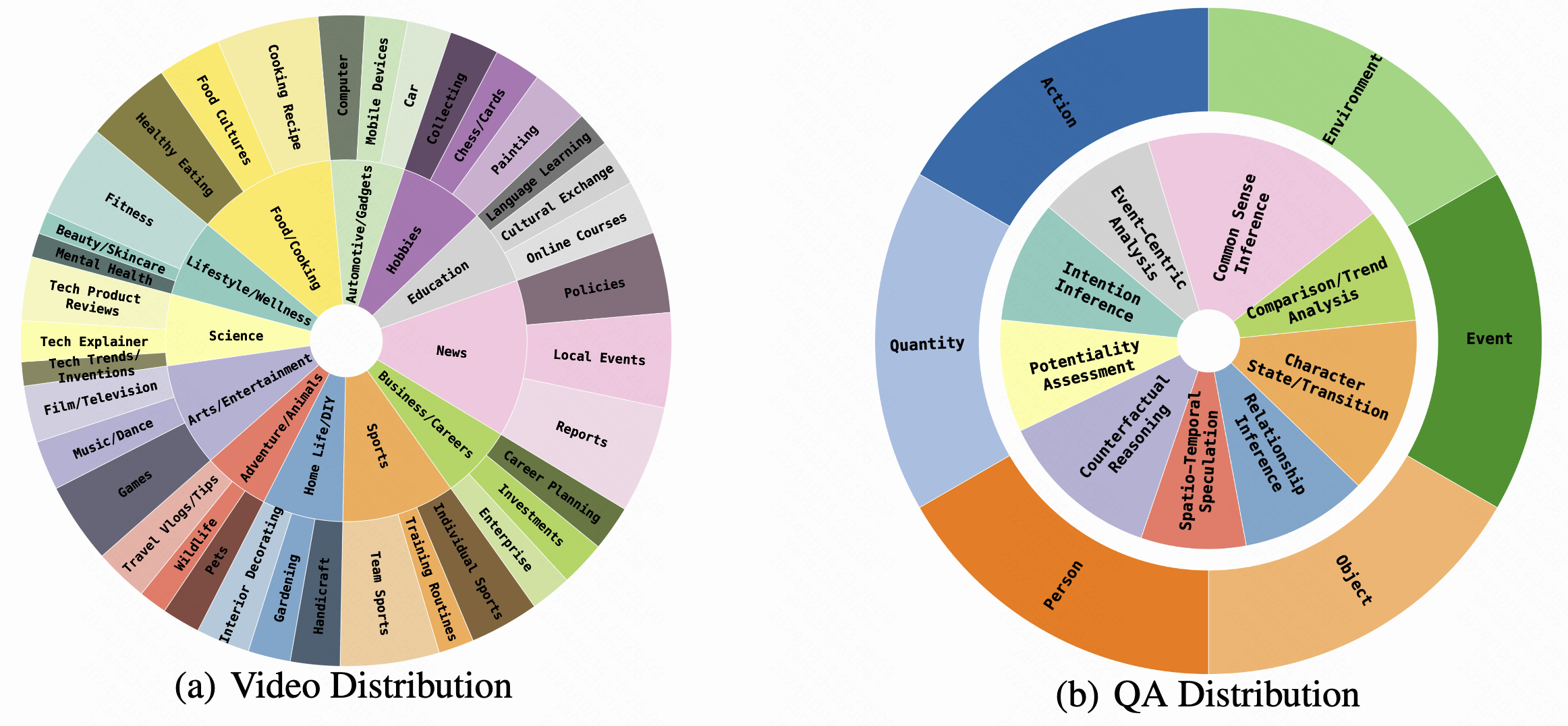
Figure 3: Distributions of videos and QA categories.
Leaderboard
To evaluate the performance of current LVLMs in streaming video understanding, we design two distinct experimental setups within the SVBench evaluation set to rigorously assess the capabilities of these LVLMs.
| Model | Type | Size | F/FPS | Dialogue Evaluation | Streaming Evaluation | AVG | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SA | CC | LC | TU | IC | OS | SA | CC | LC | TU | IC | OS | |||||
| Open-source LVLMs | ||||||||||||||||
| MovieChat | VideoLLM | 7B | 2048 | 20.36 | 23.74 | 28.97 | 22.80 | 20.51 | 22.72 | 18.92 | 22.38 | 26.77 | 20.46 | 20.98 | 19.64 | 21.18 |
| Video-ChatGPT | VideoLLM | 7B | 100 | 28.01 | 34.04 | 40.89 | 35.66 | 29.59 | 32.24 | 22.84 | 28.44 | 33.93 | 26.31 | 26.43 | 25.02 | 28.63 |
| Video-LLaVA | VideoLLM | 7B | 8 | 31.85 | 38.38 | 44.93 | 41.54 | 32.80 | 36.49 | 26.95 | 33.68 | 39.00 | 31.83 | 31.53 | 29.89 | 33.19 |
| TimeChat | VideoLLM | 7B | 16 | 31.09 | 38.57 | 45.52 | 43.37 | 31.10 | 36.24 | 27.14 | 34.42 | 39.78 | 36.80 | 31.71 | 31.15 | 33.70 |
| LLaVA-NeXT | VideoLLM | 7B | 16 | 37.71 | 44.59 | 52.05 | 41.80 | 36.58 | 41.40 | 34.29 | 39.68 | 47.65 | 35.33 | 36.68 | 36.12 | 38.76 |
| ShareGPT4Video | VideoLLM | 8B | 16 | 36.26 | 43.68 | 50.12 | 47.33 | 37.25 | 41.76 | 33.14 | 40.48 | 46.01 | 38.15 | 37.81 | 37.10 | 39.43 |
| Flash-VStream | VideoLLM | 7B | 8 | 37.54 | 44.74 | 51.02 | 47.95 | 37.94 | 42.72 | 35.71 | 44.24 | 48.49 | 38.95 | 39.00 | 38.80 | 40.76 |
| InternVL2 | ImageLLM | 8B | 8 | 40.53 | 46.77 | 52.38 | 46.97 | 40.35 | 44.48 | 38.92 | 45.42 | 50.45 | 41.53 | 42.35 | 41.62 | 43.05 |
| VILA | ImageLLM | 8B | 8 | 43.23 | 49.30 | 55.59 | 52.47 | 41.27 | 47.07 | 38.19 | 44.27 | 49.18 | 41.29 | 40.55 | 40.38 | 43.73 |
| VideoLLaMA2 | VideoLLM | 7B | 8 | 42.50 | 49.88 | 55.96 | 52.23 | 41.40 | 47.10 | 38.95 | 46.11 | 51.77 | 43.69 | 42.22 | 42.77 | 44.94 |
| InternLM-XC2.5 | VideoLLM | 7B | 32 | 46.51 | 53.16 | 59.84 | 52.94 | 45.87 | 50.71 | 52.62 | 58.55 | 62.89 | 53.98 | 54.39 | 54.39 | 52.55 |
| MiniCPM-V 2.6 | ImageLLM | 8B | 64 | 51.70 | 59.50 | 65.33 | 61.72 | 50.09 | 56.63 | 46.44 | 52.73 | 58.35 | 53.48 | 48.32 | 49.67 | 53.15 |
| Qwen2-VL | ImageLLM | 7B | 8 | 50.47 | 57.71 | 63.46 | 60.77 | 49.44 | 55.29 | 48.38 | 55.17 | 59.91 | 52.04 | 51.42 | 51.39 | 53.34 |
| Closed-source LVLMs | ||||||||||||||||
| Gemini 1.5 Pro | - | - | 1fps | 49.07 | 56.15 | 62.24 | 58.36 | 47.72 | 53.68 | 49.35 | 55.77 | 60.41 | 52.89 | 51.11 | 51.55 | 52.62 |
| GPT-4V | - | - | 10 | 56.03 | 62.61 | 69.09 | 65.36 | 53.73 | 60.30 | 56.37 | 61.41 | 65.80 | 59.18 | 57.16 | 57.93 | 59.12 |
| GPT-4o | - | - | 25 | 58.26 | 64.76 | 70.75 | 67.68 | 55.82 | 62.57 | 57.99 | 63.52 | 67.72 | 60.18 | 59.25 | 59.97 | 61.27 |
Table 1: Evaluation results of various models on SVBench in dialogue and streaming evaluation.
Comparisons with Existing Benchmarks
Avg. Q/V: the average number of QA pairs per video. Open-Domain: whether the video sources are diverse. Long: whether the average video length is greater than 2 minutes. Dialogue: whether there are contextual connections between QA pairs. Streaming: whether the QA pairs can be tested in sync with the video over time.
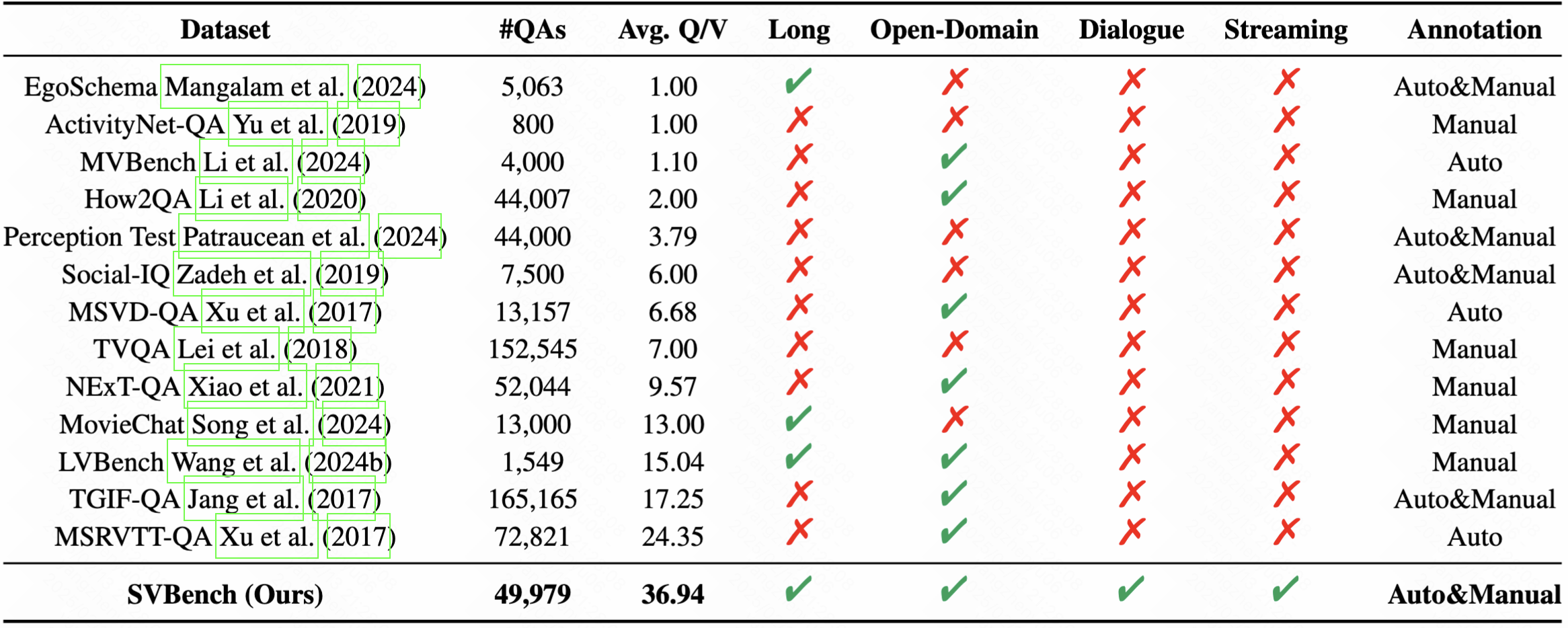
Table 2: The comparison of different datasets.
StreamingChat
Built upon InternVL2, we develop a streaming LVLM baseline named StreamingChat. It comprises a vision encoder (InternViT), an MLP projector, and an LLM (InternLM2).
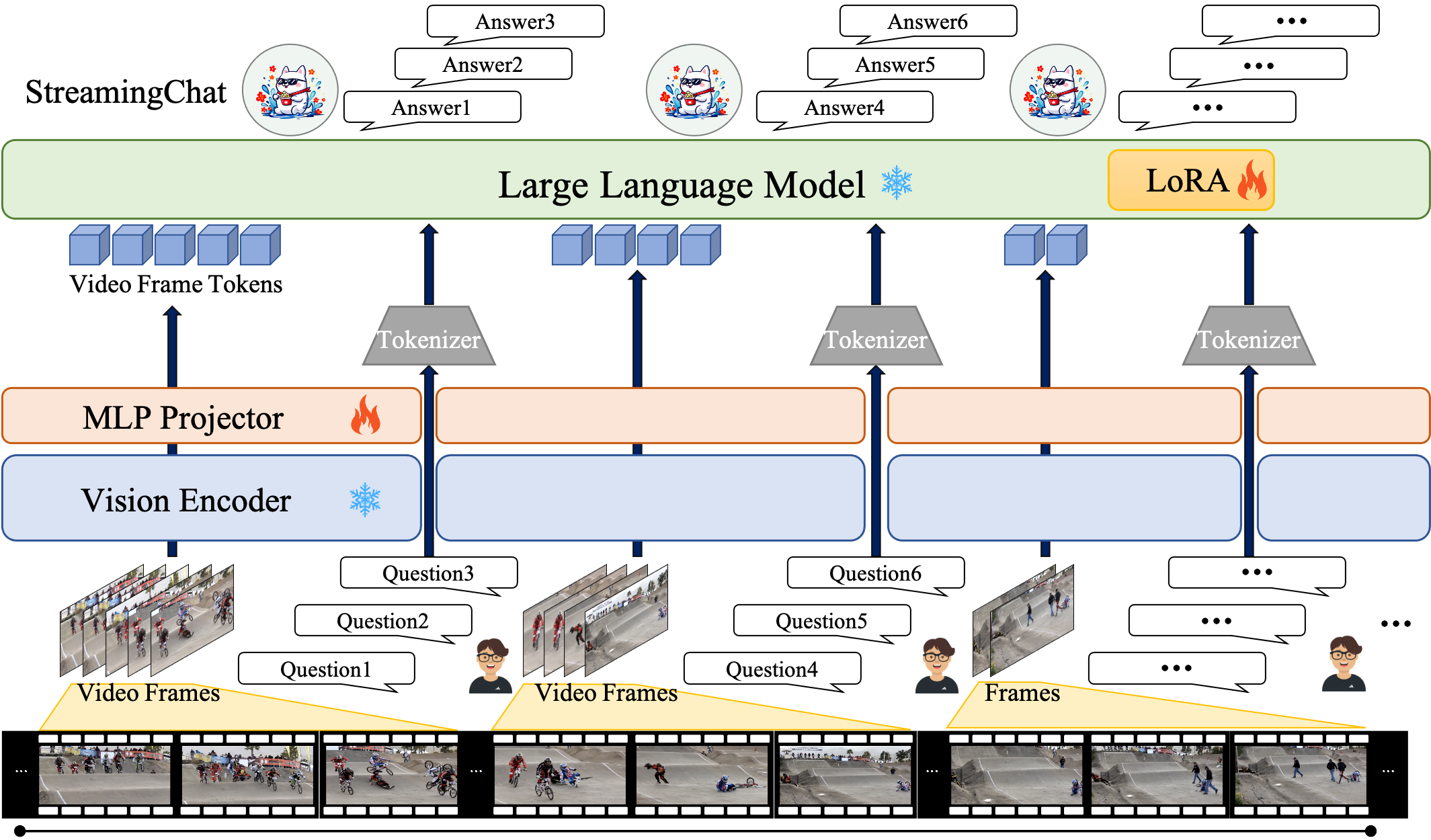
Figure 4: Architecture of the proposed StreamingChat model.
Citation
@article{yang2025svbench,
title={SVBench: A Benchmark with Temporal Multi-Turn Dialogues for Streaming Video Understanding},
author={Yang, Zhenyu and Hu, Yuhang and Du, Zemin and Xue, Dizhan and Qian, Shengsheng and Wu, Jiahong and Yang, Fan and Dong, Weiming and Xu, Changsheng},
journal={arXiv preprint arXiv:2502.10810},
year={2025}
}